K-최근접 이웃(K-Nearest Neighbor)은 머신러닝에서 사용되는 분류(Classification) 알고리즘이다. 유사한 특성을 가진 데이터는 유사한 범주에 속하는 경향이 있다는 가정하에 사용한다. K-최근접 이웃 알고리즘의 개념 원리를 쉽게 이해하기 위해 그림을 참고하겠다. 아래 그림을 보자. 모든 데이터(점)에는 각각 x값과 y값이 있다. 그리고 점의 색상으로 초록/빨강으로 표시하여 분류를 나타냈다. 그리고 하얀 점은 아직 분류가 안 된 새로운 데이터다. K-최근접 이웃 알고리즘의 목적은 이렇게 새로운 점이 등장했을 때 이걸 초록이나 빨강으로 분류하는 거다. 그런데 하얀 점 주위로 원을 그려놓았고, 이 원 안에는 1개의 이웃이 있다. 이렇게 원 안에 포함될 이웃의 개수를 k라고 생각하면 된다..
본 포스팅에서는 파이썬 머신러닝 라이브러리 scikit-learn을 통해 로지스틱 회귀(Logistic Regression) 알고리즘을 통해 타이타닉 탑승객 생존 예측 예제를 소개한다. 이전 포스팅에서는 로지스틱회귀의 기초적인 개념에 대해서 간단히 짚어봤다. 이제 직접 돌려보자 sklearn LogisticRegression 사용법 실제 데이터 돌려보기 전에 사용법부터 익히고 가자. 일다 파이썬 머신러닝 라이브러리 싸이킷런을 불러오자. 이제 LogisticRegression 모델을 생성하고, 그 안에 속성들(features)과 그 레이블(labels)을 fit 시킨다. fit() 메서드는 모델에 필요한 두 가지 변수를 전달해준다. 계수 : model_coef_ 절편 : model.intercept 어쨌든..
왜 정규화를 해야 하는가 머신러닝 알고리즘은 데이터가 가진 feature(특성)들을 비교하여 데이터의 패턴을 찾는다. 그런데 여기서 주의해야 할 점이 있다. 데이터가 가진 feature의 스케일이 심하게 차이가 나는 경우 문제가 되기 때문이다. 예를 들어 '주택'에 관한 정보가 담긴 데이터를 생각해보자. 그 안에 feature로 방의 개수(개), 얼마나 오래 전에 지어졌는지(년) 같은 것들이 포함될 수 있을거다. 그리고 여기서 머신러닝 알고리즘을 통해 어느 집이 가장 적합한지 예측을 시도한다고 해보자. 그러면 각 데이터 포인트를 비교할 때 더 큰 스케일을 가진 feature, 즉 얼마나 오래 전에 지어졌는지(년)에 따라 그 데이터가 완전히 좌지우지 되는 꼴이다. 아래 그림을 보면 이해가 쉬울 것 같다. ..
sklearn LinearRegression 사용법 실제 데이터를 돌려보기 전에 사용법부터 익히고 가자. 일단 그 유명한 파이썬 머신러닝 라이브러리 싸이킷런을 불러오자 이제 LinearRegression 모델을 생성하고, 그 안에 X, y 데이터를 fit 시킨다. fit() 메서드는 선형 회귀 모델에 필요한 두 가지 변수를 전달하는거다. 기울기 : line_fitter.coef_ 절편 : line_fitter.intercept_ 어쨌든 이게 끝이다. 이렇게 하면 새로운 X 값을 넣어 y값을 예측할 수 있게 된다. 만약 기울기와 절편을 알고싶다면 line_fitter.coef_, line_fitter.intercept_를 직접 찍어보면 된다. 그리고 선형회귀 개념 포스팅에서 수렴할 때까지 얼마나 반복할 것..
이전에 선형회귀에 대한 개념을 소개한 바 있다. X의 값에 따라 Y값이 어떻게 달라질지 예측하는, 기울기와 절편만 있는 단순한 1차 방정식 y = m\*X + b로 설명했는데, 이건 그냥 단순선형회귀라고 부른다. (만약 선형회귀의 개념이 생소하다면 반드시 알고 넘어가야 하니, 이 글을 참고하자. 아무튼 우리가 사는 세상은 단순선형회귀로 설명할 수 있을만큼 그렇게 단순하지 않다. 고려해야하는 변수 X가 하나가 아니라는 의미다. 예를 들어 주택 임대료를 예측한다고 했을 때, 주택의 면적만 고려해서 예측하면 단순회귀가 되겠지만 지어진지 얼마나 오래되었는지, 지하철역과 거리가 얼마나 가까운지 등 다양한 요소의 영향을 받는다. 결국 주택 임대료 y를 예측하려면 여러 개의 변수 x를 포함해야 하는 거다. 이를 다중..
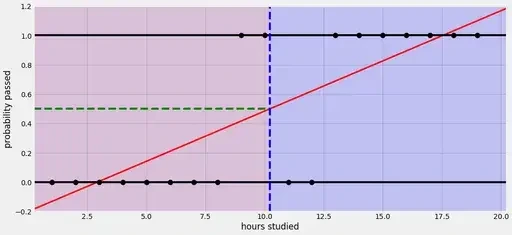
로지스틱 회귀란? 로지스틱 회귀 알고리즘은 2진 분류 모델로 사용되고 있다. 따라서 로지스틱 회귀(Logistic Regression)는 회귀를 사용하여 데이터가 어떤 범주에 속할 확률을 0과 1 사이의 값으로 예측하고 그 확률에 따라 가능성이 더 높은 범주에 속하는 것으로 분류해주는 지도 학습 알고리즘이다. 스팸 메일 분류기 같은 예시를 생각하면 쉽다. 어떤 메일을 받았을 때 그것이 스팸일 확률이 0.5 이상이면 spam으로 분류하고, 확률이 0.5보다 작은 경우 ham으로 분류하는거다. 이렇게 데이터가 2개의 범주 중 하나에 속하도록 결정하는 것을 2진 분류(binary classification)라고 한다. 로지스틱 회귀를 이해하려면 우선 선형 회귀(Linear Regression)에 대한 개념을 ..
선형 회귀 모델 머신러닝의 가장 큰 목적은 실제 데이터를 바탕으로 모델을 생성해서 만약 다른 입력 값을 넣었을 때 발생할 아웃풋을 예측하는 데에 있다. 이때 우리가 찾아낼 수 있는 가장 직관적이고 간단한 모델은 선(line)이다. 그래서 데이터를 놓고 그걸 가장 잘 설명할 수 있는 선을 찾는 방법을 선형회귀(Linear Regression) 분석이라 부른다. 선형 회귀 모델은 지도 학습 알고리즘으로 주로 수치 예측 문제에 사용한다. 즉, 독립변수(x)를 이용해서 숫자인 종속변수(y)를 예측하는 모델이다. 선형회귀는 독립변수 x와 종속변수 y 사이의 관계를 모델링하여 선형식을 이용해 설명한다. 선형 회귀는 수치 예측 문제에 사용하기 때문에 예측 문제와 추론 문제에 사용한다. 선형 회귀에서 발생하는 오차, ..
1. K-평균 (K-Means) 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법 선택된 포인트의 평균지점으로 이동하고 이동된 중심점에서 다시 가까운 포인트를 선택, 다시 중심점을 평균 지점으로 이동하는 프로세스를 반복적으로 수행 장점 일반적으로 군집화에서 가장 많이 사용되는 알고리즘 알고리즘이 쉽고 간결하다 단점 거리기반 알고리즘으로 속성의 개수가 매우 많을수록 군집화 정확도가 떨어짐 (PCA 차원감소 적용) 반복을 수행하는데 반복횟수가 많을 경우 매우 느려짐 몇 개의 군집을 선택해야할 지 가이드하기가 어려움 2. 평균 이동 (Mean Shift) K 평균과 유사하지만 거리 중심이 아니라 데이터가 모여있는 밀도가 가장 높은 곳으로 ..