머신러닝 알고리즘 나이브 베이즈 (Naive Bayes)를 사용하기 위해서는 일단 베이즈 정리(Bayes' Theorem)라는 걸 먼저 이해해야 한다. 본 포스팅에서는 베이즈 정리의 개념만 최대한 쉽고 단순하게 설명해본다. 베이즈 정리(Bayes' Theorem)는 새로운 사건의 확률을 계산하기 전에 이미 일어난 사건을 고려하는 것을 전제로 하는 베이즈(혹은 베이지안) 통계의 근간이라 할 수 있다. 뭔가 말이 어렵긴 한데 그냥 고등학교 때 배웠던 독립 사건과 조건부 확률을 떠올리면 된다. 아래 공식이 뭔가 익숙하지 않은가 영국의 수학자 앨런 튜링(Alan Turing)은 이 베이즈 정리를 활용해서 2차 세계대전 독일의 애니그마(Enigma) 암호를 풀어냈다고 한다. 아무튼 베이즈 정리는 머신러닝, 통계적..
의사결정나무(Decision Tree) 각 데이터들이 가진 속성들로부터 패턴을 찾아내서 분류 과제를 수행할 수 있도록 하는 지도학습 머신러닝 모델이다. 일단 이 모델의 개념만 최대한 쉽게 설명해본다. 목차는 아래와 같다. 의사결정나무란 무엇인가 지니 불순도 (Gini Impurity) 정보 획득량 (Information Gain) scikit-learn 사용법 재귀적(Recursive) 트리 빌딩 의사결정나무의 한계 요약 의사결정나무란 무엇인가 예를 들면 이런 거다. 시험에서 A를 받은 데이터를 초록색 동그라미로 표현했다고 하자. 의사결정나무는 대체 어떤 사람들이 그 A를 받았는지 나름의 기준이나 체크리스트같은 걸 만들어준다. 그래서 새로운 데이터가 들어오면 그 체크리스트를 바탕으로 하나씩 질문하고 (예..
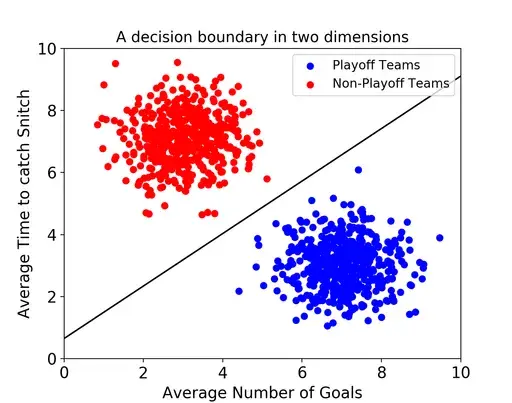
서포트 벡터 머신(SVM: Support Vector Machine)은 분류와 회귀 과제에 사용할 수 있는 강력한 머신러닝 지도학습 모델이다. 일단 이 SVM의 개념만 최대한 쉽게 설명해본다. 중간중간 파이썬 라이브러리 scikit-learn을 사용한 아주 기초적인 실습을 통해 개념 이해를 돕는다. 목차는 아래와 같다. 서포트 벡터 머신이란 최적의 결정 경계 (Decision Boundary) 마진(Margin) 이상치(Outlier)를 얼마나 허용할 것인가 커널(Kernel) 다항식(Polynomial) 방사 기저 함수(RBF: Radial Bias Function) 요약 내용이 많지 않으니 후딱 살펴보자. 1. 서포트 벡터 머신이란 서포트 벡터 머신(이하 SVM)은 결정 경계(Decision Boun..
본 포스팅에서는 두 점 사이의 거리를 구하는 여러가지 방법을 알아본다. 그런데 거리(distance)를 왜 구해야 할까? 거리는 일종의 유사도(similarity) 개념이기 때문이다. 거리가 가까울수록 그 특성(feature)들이 비슷하다는 뜻이니까. 그래서 머신러닝 알고리즘에서도 매우 널리 사용된다. 예를 들면 K-최근접 이웃(K-Nearest Neighbor) 알고리즘 같은 데에서.. 아무튼 그래서 거리 구하는 방법은 알고 있어야 한다. 수학적으로 막 깊이 파고들 필요는 없어도 개념은 이해하고 가야 알고리즘을 이해하고 사용할 수 있다. 일단 들어가기에 앞서 코드를 통해 점의 위치를 표현하는 방법을 알아야지. 뭐 별 건 아니다. 예를 들어, 흔히 말하는 x, y축만 있는 2차원에 점을 나타내고 싶다면 ..
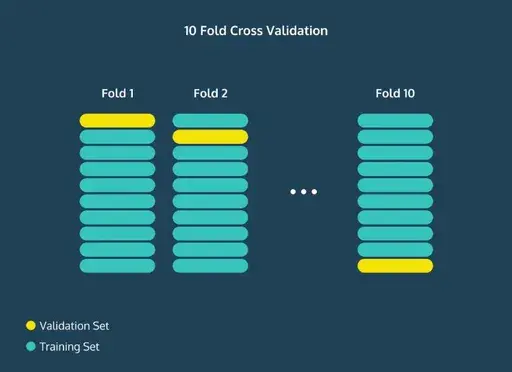
우리는 머신러닝을 통해서 예측이나 분류를 할 수 있다. 그런데 이 예측이나 분류가 얼마나 정확한지 자문하는 것이 중요하다. 분류 모델을 만들어놨는데, 그 예측이 얼마나 맞고 틀릴지 모르니까. 지도학습(supervised learning)에서는 다행히도 이미 레이블링 된(정답이 있는) 데이터가 있기 때문에 그걸 활용해서 알고리즘의 정확도를 테스트 할 수 있다. 머신러닝 모델의 효과성을 검증하기 위해 데이터를 나눌 때 보통 아래와 같이 세 개의 개념을 이해하면 된다. Training Set (학습 세트) Validation Set (검증 세트) Test Set (평가 세트) 이 중 검증 세트와 평가 세트는 사실 유사한 개념이다. 학습 세트(Training Set)와 검증 세트(Validation Set) 학..
머신러닝은 (쉽게 이야기하자면) 대량의 데이터를 알고리즘에 넣어서 일종의 규칙을 생성하고, 그 규칙에 따라 입력값을 분류하도록 하는 거다. 그래서 이 알고리즘에 제공하는 학습 데이터가 매우 중요하다. 학습 데이터의 모든 값들을 하나하나 살펴보면서 규칙을 생성하기 때문이다. Overfitting(과적합)이란 overfitting은 모델의 파라미터들을 학습 데이터에 너무 가깝게 맞췄을 때 발생하는 현상이다. 무슨 뜻인고 하니.. 학습 데이터가 실제 세계에서 나타나는 방식과 완전히 똑같을 거라고 가정해버리는 거다. 그래서 학습 데이터 세트에 속한 각각의 개별 데이터들을 완벽하게 설명하기 위한 모델을 생성해버린다. 일단 말로만 들었을 땐 좋을 수도 있는데 정말 현실이 그러할까? 아래 그림을 보자. 각 점들은 학..
KNN은 일반적으로 분류(Classification)에 사용되는 지도학습 알고리즘이다. KNN 개념 이해하기 그러나 이걸로 회귀(Regression)를 수행할 수도 있다. 분류(Classification)는 연속적이지 않은 레이블, 다시 말해 '무엇'인지를 예측하지만, 회귀(Regression)은 연속된 수치, 즉 '얼마나'를 예측하는 거다. 본 포스팅에서는 IMDb 영화 데이터 세트를 예로 설명하겠다. 회귀에 대한 이야기니까 당연히 '평이 좋다' vs '평이 나쁘다' 이렇게 레이블로 분류하는게 아니라 실제 IMDb 등급(별점)을 예측하는게 과제의 목표가 될 것이다. K-최근접 이웃(K-Nearest Neighbors) 회귀의 원리 K-Nearest Neighbors 알고리즘을 활용한 회귀도 결국 분류와..
본 포스팅에서는 파이썬 라이브러리 scikit-learn을 통해 KNN 알고리즘을 사용한 분류를 직접 수행하는 예제를 소개한다. 누구나 따라할 수 있는 수준으로 작성했다. KNN 알고리즘의 기초적인 내용은 간단히 짚어봤으니, 반드시 그걸 이해한 상태에서 코드를 작성해보자. sklearn KNeighboresClassifier 사용법 실제 데이터 돌려보기 전에 사용법부터 익히고 가자. 일단 그 유명한 파이썬 머신러닝 라이브러리 싸이킷런을 불러오자. 이제 KNeighborsClassifier 모델을 생성해야 하는데, 이 때 n_neighbors로 k를 정해줘야 한다. (그리고 x 데이터를 분류할 때 k개의 이웃 중 거리가 가까운 이웃의 영향을 더 많이 받도록 가중치를 설정하려면 weight = 'distan..