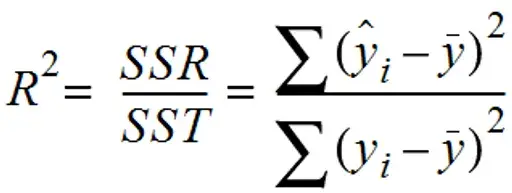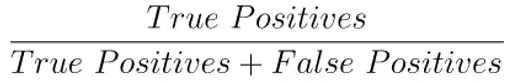분류를 수행할 수 있는 기계 학습 알고리즘을 만들고 나면, 그 분류기의 예측력을 검증/평가 해봐야 한다.
모델의 성능을 평가하려면 모델을 생성하기 전부터 애초에 데이터를 학습 세트와 평가 세트로 분리해서, 학습 세트로 모델을 만들고 평가 세트로 그 모델의 정확도를 확인하는 절차를 거친다. (자세한 내용은이 포스팅을 참고)
그런데 분류 모델 성능 평가 지표를 소개하기 전에정답을 맞히거나 틀리는 경우의 수들을 먼저 이해해야 한다.
True Positive: 실제 Positive인 정답을 Positive라고 예측(True)
True Negative: 실제 Negative인 정답을 Negative라고 예측 (True)
False Positive: 실제 Negative인 정답을 Positive라고 예측 (False) - Type Ⅰ error
False Negative: 실제 Positive인 정답을 Negative라고 예측 (False) - Type Ⅱ error
여기서 그 유명한 1종 오류, 2종 오류의 개념이 등장한다. 이 두 유형의 오류는 분류 과제의 성격에 따라 경중이 다르다.
예를 들어 중고차 성능 판별 과제에서는 1종 오류(False Positive), 즉 좋은 자동차라 예측하고 구매하였지만 실제로는 좋지 않은 자동차였을 경우가 더 치명적이다. 좋은 중고차를 나쁜 차로 예측해서 구매하지 않더라도 손해볼 것이 없지만 나쁜 중고차를 좋은 차로 잘못 예측하여 구매하는 건 굉장한 손해니까.
그러나 분류 과제가 암환자 진단이라면 2종 오류(False Negative), 즉 암 환자를 건강하다고 판별하는 경우가 훨씬 치명적이다. 그 사람의 생명이 위험해질 수 있으니까.
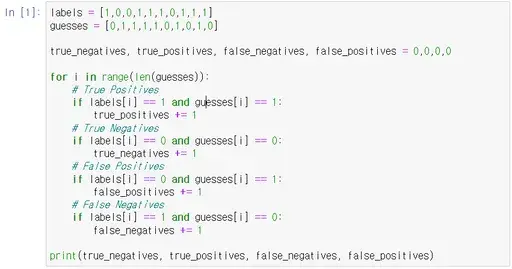
아무튼 이 개념을 파이썬 코드로 표현해보면 아래와 같다. (정답 labels와 예측한 값 guesses이 있을 때)
계산된 값을 보면 각각 3, 0, 3, 4 순으로 나온다.
이제 이 개념들을 가지고 분류 모델의 성능을 평가할 수 있는 지표를 총 4개 소개하고자 한다.
Accuracy
Recall
Precision
F1 Score
하나씩 자세히 살펴보자.
1. Accuracy (정확도)
accuracy는 다음과 같이 정의할 수 있다.
전체 예측 건수에서 정답을 맞힌 건수의 비율이다. (여기서 정답을 맞힐 때 답이 Positive든 Negative든 상관 없다. 맞히기만 하면 된다.)
Accuracy의 단점
예를 들면 내일 서울에 시간당 1m 이상의 눈이 내릴지 여부를 예측한다고 해보자. 그땐 뭐 머신러닝이고 뭐고 할 거 없이 나 혼자서도 매우 정확한 분류기를 만들 수 있다. 그냥 무조건 Negative를 예측하면 이 분류기는 99.9%의 accuracy를 나타낼 거다. 그 정도 눈 내리는 날은 거의 없으니까. 이 분류기의 정답을 True Negative로만 잔뜩 맞히는 셈이다. True Positive는 하나도 발견하지 못하고.
이런 상황을정확도 역설(Accuracy Paradox)라고 부른다.
그래서 이렇게실제 데이터에 Negative 비율이 너무 높아서희박한 가능성으로 발생할 상황에 대해 제대로된 분류를 해주는지 평가해줄 지표는 바로 recall(재현율)이다.
2. Recall (재현율)
recall은 다음과 같이 정의할 수 있다.
실제로 정답이 True인 것들 중에서 분류기가 True로 예측한 비율이다. 그래서 애초에 True가 발생하는 확률이 적을 때 사용하면 좋다.
그래서 위에서 예로 들었던 시간당 1m 이상의 눈이 내릴지 예측하는 과제에 적절한 거다. 그러면 실제로 그렇게 눈이 내린 날짜 중 몇 개나 맞히는지 확인할 수 있으니까. 만약 여기서 언제나 False로 예측하는 분류기가 있다면 accuracy는 거의 99%를 넘기겠지만, True Positive를 찾을 수 없으니 recall이 0이 된다.
Recall의 단점
그러나 안타깝게도 recall 또한 완벽한 통계 지표가 아니다. 시간당 적설량 1m 이상이 될지 분류하는 과제에서 언제나 True만 답하는 분류기가 있다고 해보자. 그러면 accuracy는 낮지만 눈이 많이 온 날에 대해서만큼은 정확하게 맞힐 수 있기 때문에 recall은 1이 된다. 이 역시 말이 안 되는 지표다.
3. Precision (정밀도)
precision은 다음과 같이 정의할 수 있다.
분류기가 눈이 많이 내릴 것이라고 예측한 날 중에 실제로 눈이 많이 내린 날의 비율을 구하는 것이다.
그래서 언제나 True만 답하는 분류기가 있다면 recall은 1로 나오겠지만, precision은 0에 가까울 거다. 시간당 1m 이상 눈 내리는 날이 며칠이나 되겠는가.
Precision의 단점
결국 precision을 사용할 때의 단점은 곧 recall을 사용할 때의 장점이 되기도 한다.recall과 precision은 서로 반대 개념의 지표이기 때문이다. 하나가 내려가면 다른 하나는 올라갈 수밖에 없다.
그래서 알고리즘을 평가할 때 recall과 precision 모두 나름대로 유용한 지표이긴 하지만, 그 알고리즘의 성능을 충분히, 효과적으로 표현하기에는 한계가 있다. 그래서 생겨난 게recall과 precision의 조화평균, F1 Score다.
4. F1 Score
F1 score는 다음과 같이 정의할 수 있다.
조화평균에 대해서는 중고등학교 때 언젠가 배웠을 거다. 나도 가물가물하긴 한데 사실 잊어버렸더라도 상관없다. 컴퓨터가 알아서 계산해줄 테니 일단 개념만 알고 가면 되지 뭐.
아무튼 흔히 말하는 평균(산술평균)을 쓰지 않고 조화평균을 구하는 이유는 recall, precision 둘 중 하나가 0에 가깝게 낮을 때 지표에 그것이 잘 반영되도록, 다시말해 두 지표를 모두 균형있게 반영하여 모델의 성능이 좋지 않다는 것을 잘 확인하기 위함이다.
예를 들어 recall, precision이 각각 1과 0.01이라는 값을 가지고 있다고 하자.
산술평균을 구하면 (1+0.01)/2 = 0.505, 즉 절반은 맞히는 것처럼 보인다. 그러나 조화평균을 구해보면 2*(1*0.01)/(1+0.01) = 0.019가 된다. 낮게 잘 나온다.
본 포스팅에서는 데이터 클러스터링(군집화)로 널리 사용되는 비지도학습 알고리즘 K-Means 클러스터링에 대해 최대한 쉽게 설명해보고자 한다. 파이썬 라이브러리 scikit-learn 사용법도 간략히 소개한다.
클러스터링, 군집화란 무엇인가
만약 우리가 다루는 데이터에 '레이블'이 붙어 있다면 지도학습, 즉 미리 가지고 있는 데이터와 레이블을 기반으로 예측이나 분류를 수행하는 모델을 만들 수 있다. 그러나 실제로는 레이블(분류)이 없는 경우가 더 많다. 물론 이렇게 별도의레이블이 없는 데이터 안에서 패턴과 구조를 발견하는 비지도 학습도 머신러닝의 큰 축이고, 그 중 가장 대표적인 비지도 학습 기술이 바로Clustering(군집화)이다.
참고로 지도학습Classification(분류)과 엄연히 다른 거다. Classification은 미리 레이블이 붙어 있는 데이터들을 학습해서 그걸 바탕으로 새로운 데이터에 대해 분류를 수행하지만, Clustering은 레이블을 모르더라도 그냥 비슷한 속성을 가진 데이터들끼리 묶어주는 역할을 하기 때문이다.
아무튼클러스터링, 군집화를 사용하는 예로는 아래와 같은 것들을 들 수 있다.
추천 엔진 : 사용자 경험을 개인화하기 위해 비슷한 제품 묶어주기
검색 엔진 : 관련 주제나 검색 결과 묶어주기
시장 세분화(segmentation) : 지역, 인구 통계, 행동에 따라 비슷한 고객들 묶어주기
군집화의 목표
군집화의 목표는서로 유사한 데이터들은 같은 그룹으로, 서로 유사하지 않은 데이터는 다른 그룹으로 분리하는 것이 된다.
그러면 자연스럽게 2개의 질문이 따라올 것이다.
몇 개의 그룹으로 묶을 것인가
데이터의 '유사도'를 어떻게 정의할 것인가 (유사한 데이터란 무엇인가)
이 두 질문을 해결할 수 있는 가장 유명한 전략이 바로K-Means알고리즘이다.
K-Means 군집화의 원리
"K"는 데이터 세트에서 찾을 것으로 예상되는 클러스터(그룹) 수를 말한다.
"Means"는 각 데이터로부터 그 데이터가 속한 클러스터의 중심까지의 평균 거리를 의미한다. (이 값을 최소화하는 게 알고리즘의 목표가 된다)
K-Means에서는 이걸 구현하기 위해 반복적인(iterative) 접근을 취한다.
일단 K개의 임의의 중심점(centroid)를 배치하고
각 데이터들을 가장 가까운 중심점으로 할당한다. (일종의 군집을 형성한다.)
군집으로 지정된 데이터들을 기반으로 해당 군집의 중심점을 업데이트한다.
2번, 3번 단계를 수렴이 될 때까지, 즉 더 이상 중심점이 업데이트 되지 않을 때까지 반복한다.
그림으로 보면 아래와 같다.
여기서 일단 k값은 2다. 그래서 (b)에서 일단 중심점 2개를 아무 데나 찍고, (c)에서는 각 데이터들을 두 개 점 중 가까운 곳으로 할당한다. (d)에서는 그렇게 군집이 지정된 상태로 중심점을 업데이트 한다. 그리고 (e)에서는 업데이트 된 중심점과 각 데이터들의 거리를 구해서 군집을 다시 할당하는 거다.
이걸 계속 반복한다.
아무튼 이렇게 군집화를 해놓으면 새로운 데이터가 들어와도 그게 어떤 군집에 속할지 할당해줄 수 있게 되는 셈이다.
파이썬 라이브러리 scikit-learn을 사용하면 K-means를 매우 쉽게 적용해볼 수 있다.
K값, 군집의 개수 정하기
군집화를 하기 위해서는 몇개의 군집이 적절할지 결정해야 하는데, 그러려면 일단 "좋은 군집"이란 무엇인지 정의할 수 있어야 한다.
만약 군집화가 잘 되었으면 각 군집의 샘플이 가까운 거리에서 오밀조밀하게 묶일 거다. 군집 내의 데이터들이 얼마나 퍼져 있는지 (혹은 얼마나 뭉쳐있는지) 응집도는inertia값으로 확인한다.inertia는 각 데이터로부터 자신이 속한 군집의 중심까지의 거리를 의미하기 때문에inertia값이 낮을수록 군집화가 더 잘됐다고 볼 수 있는 거다.
scikit-learn으로 모델을 만들었다면 이렇게 찍어보면 끝이다.
그래서 군집의 개수, 즉 k 값을 바꿔가면서 inertia를 그래프로 표시하면 보통 이런 모양새가 나온다.
k값이 증가하면 inertia 값은 감소하다가 어느정도 수준이 되면 거의 변화를 안보이게 된다. 대부분의 경우너무 많지 않은 군집으로 분류하면서도 inertia 값이 작은 상태. 이게 그나마 최선이 될 거다. 위의 그래프를 예로 들면 최적의 클러스터 수는 3으로 보인다.
이전 포스팅에서 분류에 널리 사용되는 머신러닝 알고리즘의사결정나무(Decision Tree)에 대해 알아보았다. 의사결정나무는 매우 훌륭한 모델이지만, 학습 데이터에 오버피팅하는 경향이 있다. 가지치기(pruning)같은 방법을 통해 그런 부작용을 최소화하는 전략이 있긴하나 역시나 좀 부족하다.
그래서 본 포스팅에서는 의사결정트리의 오버피팅 한계를 극복하기 위한 전략으로 **랜덤 포레스트(RandomForest)라는 방법을 아주 쉽고 간단하게 소개하고자 한다.
내용이 짧으니 후딱 살펴보자.
랜덤 포레스트란
랜덤 포레스트는 분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종으로, 훈련 과정에서 구성한 다수의 결정 트리로부터 분류 또는 평균 예측치(회귀)를 출력함으로써 동작한다.
('무작위 숲'이라는 이름처럼) 랜덤 포레스트는 훈련을 통해 구성해놓은 다수의 나무들로부터 분류 결과를 취합해서 결론을 얻는, 일종의인기 투표같은 거다.
아래 그림처럼.
물론 몇몇의 나무들이 오버피팅을 보일 수는 있지만 다수의 나무를 기반으로 예측하기 때문에 그 영향력이 줄어들게 되어 좋은 일반화 성능을 보인다.
이렇게 좋은 성능을 얻기 위해 다수의 학습 알고리즘을 사용하는 걸앙상블(ensemble) 학습법이라고 부른다.
일단 랜덤 포레스트에서 각 나무들을 어떻게 생성하는지 알아야 한다. 결론부터 얘기하면.. 배깅(bagging)이라는 프로세스를 통해 나무를 만든다.
배깅(Bagging)
학습 데이터 세트에 총 1000개의 행이 있다고 해보자. 그러면 임의로 100개씩 행을 선택해서 의사결정트리를 만든게배깅(bagging)이다. 물론 이런 식으로 트리를 만들면 모두 다르겠지만 그래도 어쨌거나 학습 데이터의 일부를 기반으로 생성했다는 게 중요하다.
그리고 이 때중복을 허용해야 한다는 걸 기억하자.
1000개의 행이 있는 가방(bag)에서 임의로 100개를 뽑아 첫 번째 트리를 만들고 그 100개의 행은 가방에 도로 집어 넣는다. 그리고 다시 1000개의 행에서 또 임의로 100개를 뽑아 두 번째 트리를 만든 후 다시 가방에 집어넣고 뭐 이런 식.
Bagging Features
여기에트리를 만들 때 사용될 속성(feature)들을 제한함으로써 각 나무들에 다양성을 줘야 한다.
원래는 트리를 만들 때 모든 속성들을 살펴보고 정보 획득량이 가장 많은 속성을 선택해서 그걸 기준으로 데이터를 분할했다. 그러나 이제는각 분할에서 전체 속성들 중 일부만 고려하여 트리를 작성하도록하는 전략이다.
예를 들면 총 25개의 속성이 있는데, 그 중 5개의 속성만 뽑아서 살펴본 후 그 중 정보 획득량이 가장 높은 걸 기준으로 데이터를 분할하는 거다. 그 다음 단계에서도 다시 임의로 5개만 선택해서 살펴보고.. 이런 식이다.
그렇다면 몇개씩 속성을 뽑는 게 좋을까. 위 예처럼 총 속성이 25개면 5개, 즉전체 속성 개수의 제곱근만큼 선택하는게 가장 좋다고, 경험적으로 그렇게 나타난다고 한다. (일종의 a rule of thumb이다.)
이제 서로 다른 트리를 만들 수 있게 되었으니 이것들을 모아 '숲'을 이루도록 하면 되는거다.
scikit-learn 사용법
랜덤 포레스트는 파이썬 라이브러리 scikit-learn을 사용하면 쉽게 구현할 수 있다.
sklearn.ensemble모듈에서RandomForestClassifier를 불러오면 된다. 단, 숲을 만들 때나무의 개수를n_estimators라는 파라미터로 지정해주어야 한다.
RandomForestClassifier는 의사결정나무DecisionTreeClassifier와 거의 똑같다. 당연히.fit(),.predict(),.score()같은 메서드를 사용할 수 있다.
요약
랜덤 포레스트는 앙상블 머신러닝 모델이다. 다수의 의사결정 트리를 만들고, 그 나무들의 분류를 집계해서 최종적으로 분류한다.
오버피팅을 피하기 위해 임의(random)의 숲을 구성하는 거다. 다수의 나무들로부터 분류를 집계하기 때문에 오버피팅이 나타나는 나무의 영향력을 줄일 수 있다.
랜덤 포레스트는 학습 데이터 세트에서 임의로 하위 데이터 세트를 추출하여 생성된다. 중복을 허용하기 때문에 단일 데이터가 여러번 선택될 수도 있다. 이 과정을 배깅(bagging)이라고 한다.
나무를 만들 때는 모든 속성(feature)들에서 임의로 일부를 선택하고 그 중 정보 획득량이 가장 높은 것을 기준으로 데이터를 분할한다. 만약 데이터 세트에 n개의 속성이 있는 경우 n제곱근 개수만큼 무작위로 선택하는 것이 일반적이다.
이전 포스팅에서 나이브 베이즈를 사용해서 텍스트를 어떻게 분류할 수 있는지 정말 간단한 예제를 통해 살펴보았다.
이번에는 파이썬 머신러닝 라이브러리 scikit-learn에서 실제로 어떻게 구현하고 동작하는지 코드를 알아볼 차례.
scikit-learn 사용법
1. CounterVectorizer
scikit-learn에서 Naive Bayes 분류기를 사용하기 전에 일단 자연어(텍스트)로 이루어진 문서들을 1과 0 밖에 모르는 컴퓨터가 이해할 수 있는 형식으로 변환해야 할 거다. feature extraction,어휘(특성) 추출과정이라 볼 수 있다.
.fit()
일단CounterVectorizer라는 객체를 만든 후,fit()메소드를 호출해서 학습 데이터 세트에 등장하는 어휘를 가르쳐놓아야 한다.
예를 들어 아래와 같이 코드를 작성하면
"첫번째", "문서", "테스트", "두번째" 이렇게 총 4개의 어휘를 학습한 CountVectorizer를 만들게 된다.
못 믿겠다면vectorizer.vocabulary_를 출력해보면 된다. 이렇게 뜰 거다.
고유한 어휘가 딕셔너리처럼 각각의 인덱스를 가지고 있다.
.transform()
어휘 사전을 만들었으니 이제.transform()메서드를 호출할 수 있다..transform()은 문자열 목록을 가져와 미리 학습해놓은 사전을 기반으로 어휘의 빈도를 세주는 거다.
아래와 같이공백으로 구분되는 문자열로 가져와서 넣어주면
counts에는 각 어휘가 등장한 빈도수가 저장되는 거다. counts.toarray()를 출력해보면 [[1 0 1 2]]와 같은 array를 볼 수 있다. 위에서 학습된 인덱스에 따라 개수를 세주었다. 그리고 "직접"이라는 단어는 애초에 사전에 등록된 단어가 아니기 때문에 고려하지 않는다.
이렇게 텍스트를 컴퓨터가 이해할 수 있는 숫자로 변환시켜놓은 셈이니 이제 나이브 베이즈를 본격적으로 사용해볼 수 있다.
2. MultinomialNB
나이브 베이즈 분류기를 학습시킬 때는 당연히 2개의 파라미터가 필요하다. 위에서 여러 문서들을 .transform() 해놓은문서-단어 행렬과 그 문서들이 어떤 분류에 속하는지레이블을 준비해서 넣어주면 된다.
이제 새로운 문서가 등장했을 때 어떤 분류로 속할지 예측을 할 수 있다.
단! 텍스트를 바로 넣는다고 되는 게 아니다. 위에서 모델을 학습시키기 위해 학습 데이터를 문서-단어 행렬로 transform 한 것처럼 새로운 텍스트도 transform해서 넣어줘야 한다.
.predict_proba()는 각 레이블로 분류될 확률을 돌려준다. 베이즈 정리로 해당 문서가 어떤 분류에 속할 확률을 각각 다 계산할 수 있기 때문이다.
나이브 베이즈 분류기를 구현하는 방법은 일단 여기까지다.
주요 내용을 다시 간단히 요약해보자.
요약
베이즈 정리에서 사용되는 확률을 계산하려면 레이블이 지정된 데이터 세트가 필요하다.
데이터 세트에 포함된 문서에서 등장하는 어휘들이 곧 특성(feature)이다. 그리고 베이즈 정리를 적용하기 위해 이 특성(어휘)들은 모두 독립적인 것으로 가정한다.
베이즈 정리를 사용하면 어떤 문서가 있을 때 그것이 특정 레이블에 속할 확률, P(레이블|문서)를 계산할 수 있으며, 이 중 확률이 가장 높은 레이블로 예측을 하게 된다.
뭐 이렇게 간단해보이긴 하지만 사실 텍스트(문서)를 나이브 베이즈로 제대로 분류하려면 그 전에 꽤 복잡한 과정을 거쳐 데이터를 잘 가공하는 게 정말 중요하다. garbage in, garbage out이라는 거..
뭐 일단 간단하고 일반적인 작업으로는 이런 게 있겠다.
문장 부호, 불용어 등을 제거한다.
모든 단어를 소문자로 통일한다. (한국어는 해당사항 없지만)
ngram 모델을 사용한다. 예를 들어 "이 음식은 너무 맛있다"는 문서가 있다면 여기서 feature는 "이", "음식은", "너무", "맛있다"가 될 것이다. 그러나 만약 bigram 모델을 사용하면 "이 음식은", "음식은 너무", "너무 맛있다"가 된다. 나이브 베이즈에서는 애초에 각 어휘들이 독립적이라고 가정하는데 이렇게 bigram 모델을 사용하면 연달아 등장하는 어휘를 고려하는 셈이니 조금 나아지는 편이다.
형태소 단위로 쪼개서 집어 넣는다. 예를 들면 "공부하다", "공부했다", "공부하는" 등의 다양한 어휘가 등장할 때 이것들 각각을 어휘로 보지 않고 "공부하-"라는 대표형으로 묶어서 보는게 효과적이기 때문이다.
특정 품사들만 선택해서 사용한다. 형태소 분석을 하면 각 어휘가 어떤 품사를 지니는지(태깅) 알 수 있기 때문에 이걸 바탕으로 일반명사, 고유명사, 형용사, 동사, 일반부사 위주로 사용하면 결과가 더 좋을 수도 있다. 물론 케바케다. 게다가 형태소를 나누는 기준이나 체계도 딱 정해져 있는 건 아니라..
그런데 여기서 만약 B를 데이터라고 생각하고, A를 레이블이라고 생각하면 일종의 분류기가 되는 셈이다.
B라는 데이터가 주어졌을 때 A라는 레이블로 분류될 확률을 계산하는 거니까.
본 포스팅에서는 어떤 쇼핑몰에 새로 작성된 리뷰를 읽고, 그게 긍정 리뷰인지 부정 리뷰인지 분류하는 예를 살펴보자. (텍스트를 분류하는 것이기 때문에 조금 생소할 수도 있다.)
"침대가 정말 부드럽다"라는 텍스트가 positive 리뷰인지 분류하려면 베이즈 정리를 바탕으로 계산한다.
이 식을 구성하는 것들을 하나씩 계산해보자.
P(positive)는 전체 리뷰 문서 중 긍정 리뷰의 비율이다. 간단하다.
P(review | positive)는 "침대가 정말 부드럽다"라는 review가 있을 때이 텍스트를 구성하는 각 단어들이 positive 리뷰에서 등장할 확률을 의미한다.
그런데 이걸 찾으려면일단 "각 단어들이 등장할 확률은 독립적이다"라는 가정을 해야 한다.한 단어가 등장하는 게 다른 단어가 나타날 확률에 영향을 미치지 않는 뜻이다.
물론 실제 상황에서는 이럴 가능성이 매우 적으니까엄밀히 말하면 옳은 가정은 아니다.그런데 이런 무리한 가정에도 불구하고 나이브 베이즈가 매우 좋은 성능을 보이기 때문에 그냥 쓰는 거다.그래서 나이브(naive)라는 표현을 붙여 놓은 거다. 순진한.. 뭔가 좀 투박하거나 어설픈..?
예를 들어P("침대가" | positive)는 positive 리뷰 데이터 세트 전체 단어 개수 중 "침대가"라는 단어 개수의 비율이 될 거다.
스무딩 (smoothing)
그러나 만약 "침대가"라는 단어가 긍정 리뷰데이터 세트에서 한 번도 등장하지 않은 단어라면 어떻게 될까? 이 경우P("침대가" | positive)값은 0이 되기 때문에P("이 침대는 정말 부드럽다" | positive)까지 0이 되어 버린다. 아주 희귀한(?) 단어나 오타 같은 게 있을 때 특히 문제다.
그래서 이 문제를 해결하기 위해스무딩(smoothing)이라는 기술을 사용해야 한다. 뭐 별 건 아니다. 분자에는 1을 더하고 분모에는 N을 더해서 부드럽게(?) 만들어주는 거다. 여기서 N은 데이터 세트에 등장하는 고유한 단어 개수다.
아무튼 여기까지 하면 분자는 다 구할 줄 아는 거다.
이제 분모를 살펴보자.
P(review)는 사실 위에서 구한P(review | positive)랑 똑같이 생각하면 된다. 리뷰 텍스트가 positive라고 가정하지 않는다는 차이만 있을 뿐이니까.
그리고 어차피 여기서는 positive 아니면 negative로 분류될 거라서, 각각의 레이블로 분류될 확률을 계산하고 비교하게 될 텐데.. 아래 식을 보면 알겠지만